
链表在 Redis 中有广泛的应用,比如列表键的实现之一就是链表。当一个列表键包含了数量比较多的元素,或者列表中包含的元素都是比较长的字符串的时候,Redis 就会使用链表来作为列表键的底层实现。
adlist 作为曾经的双向链表中的一种实现,现在的版本已经少了很多用到的地方,但是我们还是先来介绍它。
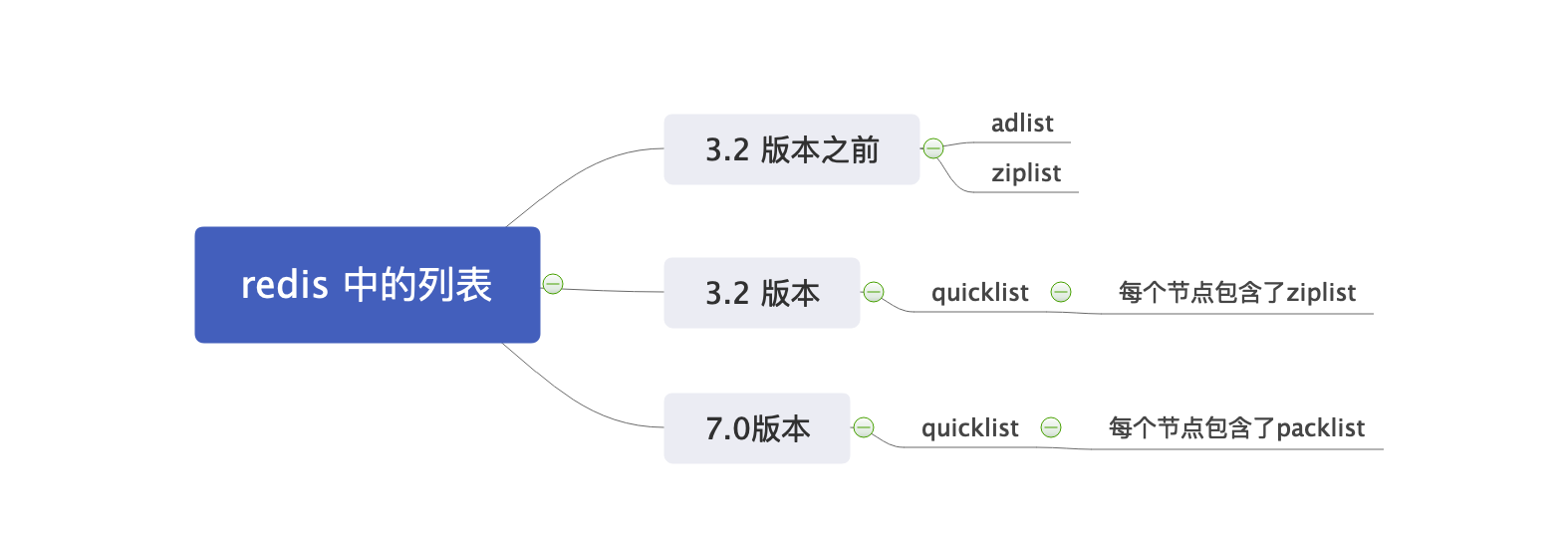
1 Redis adlist 发展历程
1.1 Redis 中的 list 都是双向链表组成么? 不是!
1.1.1 Redis 3.2 版本之前
在Redis 3.2版本之前,列表数据类型是通过双向链表(linked list)或压缩列表(ziplist)来实现的。Redis 的列表数据结构采用了两种不同的底层实现,以便根据列表的使用场景选择最优的存储方式:双向链表(linked list)和压缩列表(ziplist)。
1.1.1.1 双向链表
当列表包含的元素较多或者列表中元素的大小较大时,Redis 会采用双向链表作为底层实现。双向链表支持在两端快速添加或删除元素,且元素数量和元素大小对性能的影响较小。由于每个元素都是独立的节点,双向链表在处理大量数据时具有良好的性能表现。
1.1.1.2 压缩列表(Ziplist)
压缩列表是一种为节省内存而设计的紧凑数据结构,它在列表元素较少且每个元素占用空间不大时使用。压缩列表通过将所有元素紧凑地存储在连续的内存区域中来减少内存占用。当对列表执行添加或删除操作时,可能需要重新分配和移动内存,这在元素数量较少时通常不是问题。但随着元素数量的增加,这种操作的开销也会增加。
1.1.1.3 选择逻辑
Redis 会根据列表的实际使用情况自动选择底层实现。具体的选择标准包括列表的长度以及列表中元素的大小。例如,当列表中的元素数量较少,并且每个元素的大小也较小,Redis 倾向于使用压缩列表以节省内存。当列表的长度增加或元素大小变大时,Redis 可能会将底层实现从压缩列表转换为双向链表,以优化操作性能。
1.1.2 Redis 3.2 版本之后
- 双向链表支持大量元素的存储,但是每个元素都需要额外的指针空间,这在存储小元素时会造成内存浪费。
- 压缩列表则是一个紧凑的数据结构,能够节省内存,但是它不适合存储大量元素,因为插入和删除操作可能需要重新分配和复制整个数据结构,导致性能问题。
为了结合两种数据结构的优点,Redis 3.2 引入了 quicklist。quicklist 是一种结合了双向链表和压缩列表的数据结构,它是由多个压缩列表节点组成的双向链表。这种设计既能够保持较高的内存效率,又能够提供良好的操作性能,特别是在列表元素非常多或者非常少的情况下。
quicklist: 表示整个列表,它包含了指向头部和尾部的指针、总节点数、总元素数以及一些配置项(如节点填充因子、压缩深度等)。
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; // 总元素数量
unsigned long len; // 节点数量
int fill : QL_FILL_BITS; // 节点填充因子
unsigned int compress : QL_COMP_BITS; // 压缩深度
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
quicklistNode: 表示 quicklist 中的一个节点,每个节点内部使用一个 ziplist 存储数据。节点之间形成双向链表。
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; // 指向 ziplist 的指针
unsigned int sz; // ziplist 的大小
unsigned int count : 16; // ziplist 中元素的数量
unsigned int encoding : 2; // 编码方式
unsigned int container : 2;// 容器类型,目前只使用 ziplist
unsigned int recompress : 1; // 是否需要重新压缩
unsigned int attempted_compress : 1; // 是否尝试过压缩
unsigned int extra : 10; // 保留字段
} quicklistNode;
ziplist: 是一种紧凑的序列化数据结构,用于在单个 quicklistNode 中存储多个元素。ziplist 的细节在这里不展开,它基于内存连续存储,优化了空间使用。
1.1.3 Redis 7.0 版本之后
从 Redis 7.0 版本开始,quicklist 的底层实现发生了重要变化,主要是将底层存储结构从 ziplist 替换为 listpack。这个变化是为了解决 ziplist 在处理某些操作时的性能问题,同时进一步优化内存使用效率。listpack 是一种更为紧凑和高效的序列化数据结构,专为 Redis 的需求设计,以改进存储效率和操作性能。
typedef struct quicklistNode {
struct quicklistNode *prev; // 指向前一个节点的指针
struct quicklistNode *next; // 指向后一个节点的指针
unsigned char *entry; // 指向实际数据的指针,根据 container 和 encoding 的值,这里存储的可能是未压缩数据或LZF压缩后的数据
size_t sz; // entry 的大小,以字节为单位
unsigned int count : 16; // 该节点中 listpack 中元素的数量
unsigned int encoding : 2; // 数据的编码类型:RAW==1 表示数据未压缩,LZF==2 表示数据使用 LZF 算法压缩
unsigned int container : 2; // 节点容器类型:PLAIN==1 表示数据未打包,PACKED==2 表示数据被打包在 listpack 中
unsigned int recompress : 1; // 该节点之前是否被压缩过。在访问压缩节点后,如果需要保留节点解压状态,该标志会被设置
unsigned int attempted_compress : 1; // 标识该节点是否尝试过压缩但由于太小而失败
unsigned int dont_compress : 1; // 标识该节点不应被压缩,通常用于即将被访问的节点,以避免压缩和解压缩的开销
unsigned int extra : 9; // 保留的额外位,未来可能用于存储额外的信息或标志
} quicklistNode;
1.1.3.1 listpack vs. ziplist
- 更高的内存效率:
listpack通过优化元素的存储格式,减少了每个元素所需的额外空间,特别是对于小型元素。 - 改进的操作性能:
listpack在插入和删除操作上表现更优,因为它减少了内存重分配的需要,尤其是在列表的中间进行操作时。 - 更好的扩展性:
listpack设计时考虑到了未来的扩展性,使得 Redis 在添加新功能或进一步优化存储结构时更为灵活。
1.2 adlist 双向链表现在主要用于哪些地方?
1.2.1 adlist 的用途
Redis 采用了 quicklist 来替代更早版本中的纯 ziplist 或纯双向链表实现,但这并不意味着 adlist 就没有用途了。adlist作为一种基础的数据结构,在Redis的很多其他部分仍然有广泛的应用。
使用的地方还比较多,比如:
- 发布/订阅模型:
adlist可以用来管理订阅者列表,每个频道或模式都可能有多个订阅者。 - 配置/客户端列表维护:用到
adlist来维护相关的数据结构。
1.2.2 为什么保留 adlist
- 通用性:
adlist作为一种非常通用的数据结构,适用于各种场景,特别是那些需要双向遍历或者频繁在两端插入删除操作的场合。 - 独立性:Redis的数据结构设计原则之一是根据使用场景选择最合适的数据结构。虽然对于列表类型数据
quicklist更优,但这并不排斥在其他场景中使用adlist。
接下来,我们本章节主要是为了讲解双向链表:
2 Redis双向链表的结构
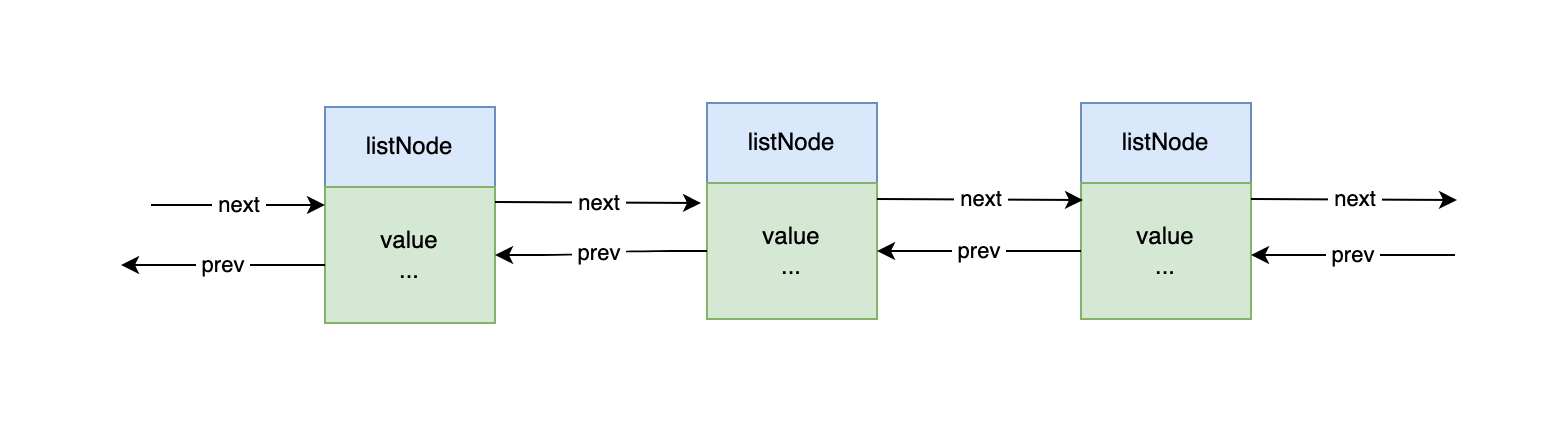
在 Redis 源代码中,双向链表主要通过以下两个结构体定义:
- listNode 结构体:表示链表中的一个节点,每个节点都有
prev和next两个指针分别指向前一个节点和后一个节点,以及一个value指针用来存储节点的值。
prev和next分别指向前一个节点和后一个节点。value用于存储节点的值,是一个void*类型,可以指向任意类型的数据。
typedef struct listNode {
struct listNode *prev; // 指向前一个节点
struct listNode *next; // 指向后一个节点
void *value;
} listNode;
- list 结构体:表示整个双向链表。
head和tail分别指向链表的头节点和尾节点。dup、free和match是函数指针,用于节点值的复制、释放和匹配操作,提供了链表操作的扩展性。len记录了链表的长度,即链表中节点的数量。
typedef struct list {
listNode *head; // 链表头节点
listNode *tail; // 链表尾节点
void *(*dup)(void *ptr); // 节点值复制函数
void (*free)(void *ptr); // 节点值释放函数
int (*match)(void *ptr, void *key); // 节点值匹配函数
unsigned long len; // 链表长度
} list;
3 常用函数源码分析
3.1 listCreate - 创建一个新的空链表
list *listCreate(void) {
struct list *list;
// 尝试为list结构体分配内存
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL; // 内存分配失败时返回NULL
// 初始化链表属性
list->head = list->tail = NULL; // 头尾节点初始化为NULL
list->len = 0; // 链表长度初始化为0
list->dup = NULL; // 节点值复制函数指针初始化为NULL
list->free = NULL; // 节点值释放函数指针初始化为NULL
list->match = NULL; // 节点值匹配函数指针初始化为NULL
return list; // 返回新创建的链表
}
3.2 listEmpty - 清空链表中的所有节点
void listEmpty(list *list) {
unsigned long len;
listNode *current, *next;
current = list->head; // 从头节点开始
len = list->len; // 获取链表长度
while(len--) { // 遍历链表
next = current->next; // 保存下一个节点的地址
if (list->free) list->free(current->value); // 如果设置了释放函数,则释放节点值
zfree(current); // 释放当前节点
current = next; // 移至下一个节点
}
list->head = list->tail = NULL; // 清空后头尾节点设为NULL
list->len = 0; // 链表长度设为0
}
3.3 listRelease - 释放整个链表
void listRelease(list *list) {
listEmpty(list); // 首先清空链表
zfree(list); // 然后释放链表结构体本身的内存
}
3.4 listAddNodeHead - 在链表头部添加一个新节点
list *listAddNodeHead(list *list, void *value) {
listNode *node;
// 为新节点分配内存
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL; // 内存分配失败时返回NULL
node->value = value; // 设置节点值
listLinkNodeHead(list, node); // 将新节点链接到链表头部
return list; // 返回链表指针
}
3.5 listLinkNodeHead - 链接新节点到链表头部
void listLinkNodeHead(list* list, listNode *node) {
if (list->len == 0) {
// 链表为空时,新节点即为头节点也是尾节点
list->head = list->tail = node;
node->prev = node->next = NULL; // 新节点的前驱和后继都设为NULL
} else {
// 链表非空时,更新头节点和新节点的指针
node->prev = NULL; // 新节点的前驱设为NULL
node->next = list->head; // 新节点的后继指向原头节点
list->head->prev = node; // 原头节点的前驱指向新节点
list->head = node; // 更新头节点为新节点
}
list->len++; // 链表长度加1
}
3.6 listAddNodeTail - 在链表尾部添加一个新节点
list *listAddNodeTail(list *list, void *value) {
listNode *node;
// 为新节点分配内存
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL; // 内存分配失败时返回NULL
node->value = value; // 设置节点值
listLinkNodeTail(list, node); // 将新节点链接到链表尾部
return list; // 返回链表指针
}
3.7 listLinkNodeTail - 链接新节点到链表尾部
void listLinkNodeTail(list *list, listNode *node) {
if (list->len == 0) {
// 如果链表为空,新节点既是头节点也是尾节点
list->head = list->tail = node;
node->prev = node->next = NULL; // 新节点的前驱和后继都设置为NULL
} else {
// 如果链表非空,插入节点到尾部,并更新尾节点
node->prev = list->tail; // 新节点的前驱指向原尾节点
node->next = NULL; // 新节点的后继设置为NULL
list->tail->next = node; // 原尾节点的后继指向新节点
list->tail = node; // 更新尾节点为新节点
}
list->len++; // 链表长度加1
}
3.8 listInsertNode - 在指定节点前或后插入一个新节点
list *listInsertNode(list *list, listNode *old_node, void *value, int after) {
listNode *node;
// 为新节点分配内存
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL; // 内存分配失败时返回NULL
node->value = value; // 设置新节点的值
if (after) {
// 在指定节点之后插入新节点
node->prev = old_node; // 新节点的前驱指向指定节点
node->next = old_node->next; // 新节点的后继指向指定节点的后继
if (list->tail == old_node) {
// 如果指定节点是尾节点,更新链表的尾节点为新节点
list->tail = node;
}
} else {
// 在指定节点之前插入新节点
node->next = old_node; // 新节点的后继指向指定节点
node->prev = old_node->prev; // 新节点的前驱指向指定节点的前驱
if (list->head == old_node) {
// 如果指定节点是头节点,更新链表的头节点为新节点
list->head = node;
}
}
if (node->prev != NULL) {
// 更新新节点前驱节点的后继为新节点
node->prev->next = node;
}
if (node->next != NULL) {
// 更新新节点后继节点的前驱为新节点
node->next->prev = node;
}
list->len++; // 链表长度加1
return list; // 返回链表指针
}
3.9 listDelNode - 从链表中删除指定节点
void listDelNode(list *list, listNode *node) {
listUnlinkNode(list, node); // 从链表中解链接指定节点
if (list->free) list->free(node->value); // 如果设置了释放函数,则释放节点值
zfree(node); // 释放节点本身
}
3.10 listUnlinkNode - 从链表中解链接指定节点但不释放
void listUnlinkNode(list *list, listNode *node) {
if (node->prev)
node->prev->next = node->next; // 更新前驱节点的后继
else
list->head = node->next; // 如果是头节点,更新链表头
if (node->next)
node->next->prev = node->prev; // 更新后继节点的前驱
else
list->tail = node->prev; // 如果是尾节点,更新链表尾
node->next = node->prev = NULL; // 清除节点的前驱和后继指针
list->len--; // 链表长度减1
}
4 双向链表优势
- 双向遍历:双向链表支持前向和后向遍历,这在某些需要频繁访问前一个或后一个节点的场景下非常有用。
- 操作灵活:可以非常方便地在链表的头部或尾部添加或删除节点,也可以在链表中任意位置插入或删除节点,操作复杂度为
O (1)。 - 扩展性强:通过
dup、free和match函数指针,可以自定义节点值的处理逻辑,使得双向链表可以存储各种类型的数据,并进行灵活操作。
5 总结一下
在 Redis 7.0 中,adlist(即双向链表)继续扮演着重要的角色,尽管对于列表数据类型的存储已经采用了更为高效的 quicklist 数据结构。adlist 提供了灵活的数据管理方式,使其在 Redis 的许多内部机制中仍然非常有用,包括发布/订阅模型、事务管理、哈希表的冲突解决等场景。通过允许前向和后向遍历,以及在列表两端或中间任意位置高效地添加和删除元素,adlist 为 Redis 提供了一种通用且灵活的数据管理工具。尽管 Redis 7.0 引入了新的数据结构和性能优化,adlist 作为一个基础且强大的数据结构,仍然在 Redis 的多个方面发挥着核心作用。