
前面我们已经讲过布隆过滤器的原理,都理解是这么运行的,那么一般我们使用布隆过滤器,是怎么去使用呢?如果自己去实现,又是怎么实现呢?
布隆过滤器
再念一次定义:
布隆过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在 1970 年提出的,它实际上是由一个很长的二进制向量和一系列随机hash映射函数组成(说白了,就是用二进制数组存储数据的特征)。
譬如下面例子:有三个hash函数,那么“陈六”就会被三个hash函数分别hash,并且对位数组的长度,进行取余,分别hash到三个位置。

如果对原理还有不理解的地方,可以查看我的上一篇文章。
手写布隆过滤器
那么我们手写布隆过滤器的时候,首先需要一个位数组,在Java里面有一个封装好的位数组,BitSet。
简单介绍一下BitSet,也就是位图,里面实现了使用紧凑的存储空间来表示大空间的位数据。使用的时候,我们可以直接指定大小,也就是相当于创建出指定大小的位数组。
BitSet bits = new BitSet(size);
同时,BitSet提供了大量的API,基本的操作主要包括:
- 清空位数组的数据
- 翻转某一位的数据
- 设置某一位的数据
- 获取某一位的数据
- 获取当前的
bitSet的位数
下面就讲一下,写一个简单的布隆过滤器需要考虑的点:
- 位数组的大小空间,需要指定,其他相同的时候,位数组的大小越大,
hash冲突的可能性越小。 - 多个
hash函数,我们需要使用hash数组来存,hash函数需要如何设置呢?为了避免冲突,我们应该使用多个不同的质数来当种子。 - 方法:主要实现两个方法,一个往布隆过滤器里面添加元素,另一个是判断布隆过滤器是否包含某个元素。
下面是具体的实现,只是简单的模拟,不可用于生产环境,hash函数较为简单,主要是使用 hash 值得高低位进行异或,然后乘以种子,再对位数组大小进行取余数:
import java.util.BitSet;
public class MyBloomFilter {
// 默认大小
private static final int DEFAULT_SIZE = Integer.MAX_VALUE;
// 最小的大小
private static final int MIN_SIZE = 1000;
// 大小为默认大小
private int SIZE = DEFAULT_SIZE;
// hash函数的种子因子
private static final int[] HASH_SEEDS = new int[]{3, 5, 7, 11, 13, 17, 19, 23, 29, 31};
// 位数组,0/1,表示特征
private BitSet bitSet = null;
// hash函数
private HashFunction[] hashFunctions = new HashFunction[HASH_SEEDS.length];
// 无参数初始化
public MyBloomFilter() {
// 按照默认大小
init();
}
// 带参数初始化
public MyBloomFilter(int size) {
// 大小初始化小于最小的大小
if (size >= MIN_SIZE) {
SIZE = size;
}
init();
}
private void init() {
// 初始化位大小
bitSet = new BitSet(SIZE);
// 初始化hash函数
for (int i = 0; i < HASH_SEEDS.length; i++) {
hashFunctions[i] = new HashFunction(SIZE, HASH_SEEDS[i]);
}
}
// 添加元素,相当于把元素的特征添加到位数组
public void add(Object value) {
for (HashFunction f : hashFunctions) {
// 将hash计算出来的位置为true
bitSet.set(f.hash(value), true);
}
}
// 判断元素的特征是否存在于位数组
public boolean contains(Object value) {
boolean result = true;
for (HashFunction f : hashFunctions) {
result = result && bitSet.get(f.hash(value));
// hash函数只要有一个计算出为false,则直接返回
if (!result) {
return result;
}
}
return result;
}
// hash函数
public static class HashFunction {
// 位数组大小
private int size;
// hash种子
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
// hash函数
public int hash(Object value) {
if (value == null) {
return 0;
} else {
// hash值
int hash1 = value.hashCode();
// 高位的hash值
int hash2 = hash1 >>> 16;
// 合并hash值(相当于把高低位的特征结合)
int combine = hash1 ^ hash1;
// 相乘再取余
return Math.abs(combine * seed) % size;
}
}
}
public static void main(String[] args) {
Integer num1 = new Integer(12321);
Integer num2 = new Integer(12345);
MyBloomFilter myBloomFilter =new MyBloomFilter();
System.out.println(myBloomFilter.contains(num1));
System.out.println(myBloomFilter.contains(num2));
myBloomFilter.add(num1);
myBloomFilter.add(num2);
System.out.println(myBloomFilter.contains(num1));
System.out.println(myBloomFilter.contains(num2));
}
}
运行结果,符合预期:
false
false
true
true
但是上面的这种做法是不支持预期的误判率的,只是可以指定位数组的大小。
当然我们也可以提供数据量,以及期待的大致的误判率来初始化,大致的初始化代码如下:
// 带参数初始化
public BloomFilter(int num,double rate) {
// 计算位数组的大小
this.size = (int) (-num * Math.log(rate) / Math.pow(Math.log(2), 2));
// hsah 函数个数
this.hashSize = (int) (this.size * Math.log(2) / num);
// 初始化位数组
this.bitSet = new BitSet(size);
}
Redis实现
平时我们可以选择使用Redis的特性于布隆过滤器,为什么呢?因为Redis里面有类似于BitSet的指令,比如设置位数组的值:
setbit key offset value
上面的key是键,offset是偏移量,value就是1或者0。比如下面的就是将key1 的第7位置为1。
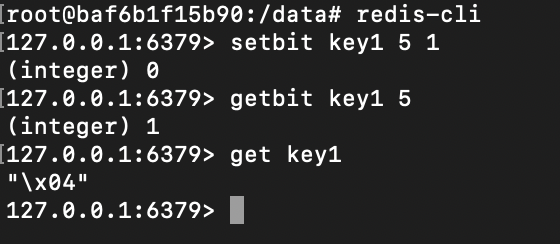
而获取某一位的数值可以使用下面这个命令:
gitbit key offset
借助redis这个功能我们可以实现优秀的布隆过滤器,但是实际上我们不需要自己去写了,Redisson这个客户端已经有较好的实现。
下面就是用法:
使用maven构建项目,首先需要导包到pom.xml:
<dependencies>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.11.2</version>
</dependency>
</dependencies>
代码如下,我使用的docker,启动的时候记得设置密码,运行的时候修改密码不起效果:
docker run -d --name redis -p 6379:6379 redis --requirepass "password"
实现的代码如下,首先需要连接上redis,然后创建redission,使用redission创建布隆过滤器,直接使用即可。(可以指定预计的数量以及期待的误判率)
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class BloomFilterTest {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
config.useSingleServer().setPassword("password");
// 相当于创建了redis的连接
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("myBloomFilter");
//初始化,预计元素数量为100000000,期待的误差率为4%
bloomFilter.tryInit(100000000,0.04);
//将号码10086插入到布隆过滤器中
bloomFilter.add("12345");
System.out.println(bloomFilter.contains("123456"));//false
System.out.println(bloomFilter.contains("12345"));//true
}
}
运行结果如下:值得注意的是,这是单台redis的情况,如果是redis集群的做法略有不同。

Google GUAVA实现
Google提供的guava包里面也提供了布隆过滤器,引入pom文件:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
具体的实现调用的代码如下,同样可以指定具体的存储数量以及预计的误判率:
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(Charsets.UTF_8),1000000,0.04);
bloomFilter.put("Sam");
System.out.println(bloomFilter.mightContain("Jane"));
System.out.println(bloomFilter.mightContain("Sam"));
}
}
执行的结果如下,符合预期
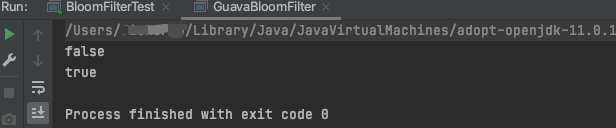
上面三种分别是手写,redis,guava实践了布隆过滤器,只是简单的用法,其实redis和guava里面的实现也可以看看,有兴趣可以了解一下,我先立一个Flag。